
In previous Aero blog posts [1, 2] we learned how the Gaia team at the University of Geneva (UNIGE) utilizes TornadoVM developed by the University of Manchester to accelerate a signal processing algorithm for large scale variable star classification for the European Space Agency’s Gaia mission.
However, besides the computational challenge described in the previous blog posts, there also exists a data challenge in dealing with the vast Gaia data for variable object classification. Storing the various time-series of scientific measurements generated by Gaia for more than 1.8 billion objects quickly reaches the peta-byte scale. Not only do we need to store the data, we also have to allow for quick querying, transformation, aggregation, and so on – both for interactive use and for feeding compute nodes in batch processing mode.
This is where Sednai comes in. Sednai designed and maintains a distributed Postgres-based solution to deal with this scale of data and compute for UNIGE. For our application, one of the many advantages of Postgres is its easy extensibility with custom user-defined functions, which allows us to perform many computations directly in-database, moving compute to where the data is located. Since the Gaia data processing consortium decided a long time ago to develop the scientific code in Java, which is not a native language of Postgres, Sednai exclusively utilized the Postgres extension plJava to provide an interface between Postgres and the Java Virtual Machine (JVM). This changed with Aero.
Even though plJava is a feature-rich, mature and actively-developed extension, it quickly became clear during the Aero project that there is a core functionality missing. Namely, that plJava can run the JVM only in a Postgres user session. That is, the Postgres master process starts a new process for a new user session, and the first time a user calls a Java function, a new and independent JVM is created in the user process itself. This is illustrated in figure 1.
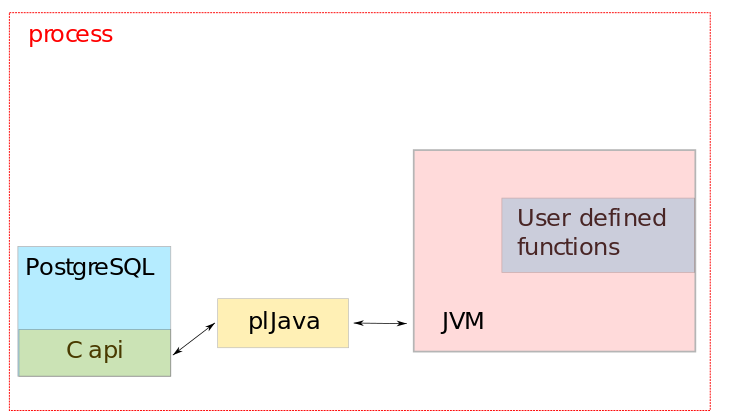
Therefore, if we were to utilize plJava to allow user-defined Java functions to run GPU-accelerated code using TornadoVM (such as in the signal processing algorithm developed by UNIGE described in the previous blog posts [1, 2]), we would quickly run into problems, as it would be difficult to control GPU resource consumption of the many different users. This would potentially lead to bad, or even terrible, user experiences.
Since the user-defined functions we consider for GPU acceleration are transformation functions, i.e., they take a user-supplied input and return a processed result, they do not require their own SPI-based database connection. Therefore, they could be run in one, or several, independent background process JVMs, shared by all users, allowing us to control the total resource consumption, as illustrated in Fig. 2.
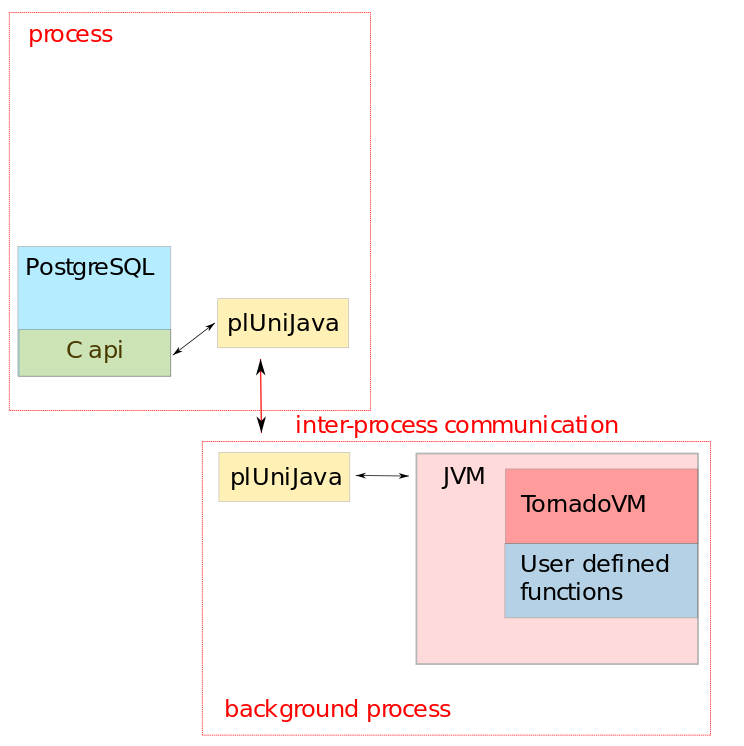
However, plJava lacks the ability to run a JVM in a background process, and introducing such a feature directly into plJava would require significant modifications of its core code base. Therefore, for simplicity, we opted to develop from scratch a new bare metal Java language handler for Postgres, which we named plUniJava, rather than trying to bend plJava to our needs. This has been feasible, because we only require a limited subset of plJava’s functionality for the functions that we intend to accelerate with TornadoVM.
So what is actually needed for such a Postgres Java language handler, technically speaking ?
First, we need to be able to run a JVM in a Postgres background process. Thanks to the dynamic background worker API of Postgres, this is straight-forward. Essentially, we just need to fill a BackgroundWorker struct with a C library and function name, plus some misc settings, and we can start a C-based JVM control function in a Postgres background process by calling RegisterDynamicBackgroundWorker.
But how to start a JVM and interact with it?
Well, that is what the Java Native Interface (JNI) is for. Our JVM control function running in a Postgres background process should control startup of the JVM via JNI, and then also perform on-demand Java function calls via JNI.
Secondly, a user process needs to be able to interact with the JVM in the background process, that is, sending function call requests and arguments to execute, and receiving the function return. This is a bit more tricky, because of operating system process isolation.
In order to communicate with the background process, we have to utilize shared memory between the background process running the JVM and a user session process. Earlier versions of Postgres require shared memory to be reserved on startup of Postgres, using the shmem_request_hook hook. Hence, the amount of shared memory we have at hand is fixed at startup. Note however that Postgres 17 improves on this with a new dynamic shared memory registry. We have not made use of it yet in plUniJava, but it is on the roadmap !
Having shared memory at hand, we still need to decide on a scheme to communicate task information, with a task being a function to be called. For simplicity, we opted for a task queuing system. User processes add task structs, which in particular contain the class and method name to be executed, to a task queue implemented as a Linked List in shared memory, and then notify background JVM processes via the SetLatch functionality of Postgres. Upon notification, background worker processes pick up the next available task from the queue, execute the desired function and write the result into the data field of the task shared memory struct. The corresponding waiting user process is then notified via SetLatch, and reads after wake-up the results from shared memory for feeding back into the ordinary Postgres data stream. Potential concurrency issues are avoided by utilizing SpinLockAcquire and SpinLockRelease each time the task queue is accessed. The shared memory layout is illustrated in figure 3.
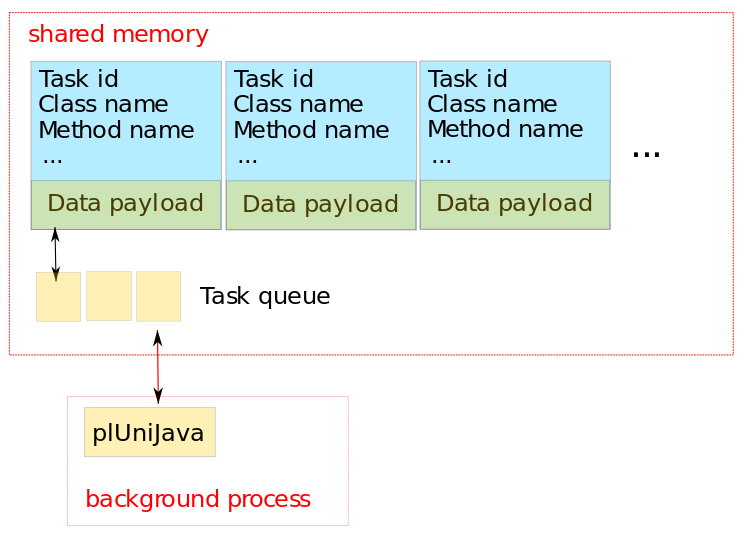
However, the price to be paid in this simplistic solution is that the number of possible simultaneously active tasks and, in particular, maximum sizes of argument and return data per task, has to be specified before-hand, and ultimately is limited by the amount of pre-reserved shared memory.
We do not claim that the above communication scheme is the most elegant or efficient solution, but it does its job, and our benchmarking implies that the overhead in running the JVM in a background process in this way is rather negligible.
There is plenty we have not talked about, such as type mapping between Postgres and Java types, or translation of Postgres function definitions to Java function signatures. Even though a basic Java language handler for Postgres can be implemented relatively fast and effortlessly for a particular application in ~3500 lines of C code, as sketched above, the effort required to build a fully-featured, swiss-knife-style general purpose handler, like plJava, grows quickly. Fortunately, a taylored minimalistic solution can be sufficient for many applications ! Perhaps also for yours ?
To get you started, we made plUniJava available here. Of course, plUniJava can also run a JVM directly in the user process, or in a per-user dedicated background process. But be warned, so far we have not implemented any security mechanisms directly into plUniJava. Therefore, any security restrictions should be placed in the Postgres level, i.e., do not let untrusted users create and run arbitrary Java functions.
If you want to learn a bit more about plUniJava, or about some of the other topics we look into in the Aero project context, we invite you to check out our recent presentation at the CERN PGday 2025. The Aero part starts at 22:50.